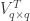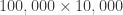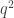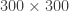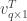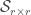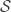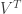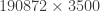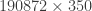For those acquainted with POD (Proper Orthogonal Decomposition), it’s very easy to throw POD at everything data analysis related. It’s such a powerful technique! For those who aren’t acquainted, I really recommend. I’ll introduce with a refresher. If you’re good, follow to the next section! We can decompose a set of N dimensional data points, which we will call here , into three matrices. Since I’m not too fond of the “fancy mathematical jargon”, let’s just start with a practical example. I have a movie of particle image velocimetry (PIV), which is a data set that contains the information of a flow in a plane where I was looking at. This movie is a vector field, meaning it is a 2D set of data (like a screen), but each “pixel” has three numbers to describe the information contained (Velocity measured, in , and direction). See the movie below and think this could very well be simulation data or any other data set!
Therefore, the movie is a 4D data set: Let’s count the dimensions: (1) Pixels in the X direction, (2) pixels in the Y direction, (3) vector component (, or ) and (4) time. Since POD can only handle normal matrices, we have to do some remodeling of the data set to fit matrix algebra, which can only handle 2D arrays of numbers. In order to do that, we need to flatten all dimensions but one. Which one should be left unflattened is up to you, but in “movies”, it makes a lot of sense to leave the time dimension unflattened, since we know that things are changing through time. Technically, you could do the POD in the spatial dimension instead, and perhaps get some insight from it, too, but for this example let’s stick to the more intuitive case where dimensions (1, 2, 3) are flattened into a column vector and dimension (4), the time dimension, is left unflattened.
If we do that, we can construct a data matrix , which has dimensionality . , the number of rows of , is the number of entries necessary to build the flattened snapshot of the movie (in our case, dimensions 1, 2, 3 are flattened in the direction, so is the number of elements in each of those dimensions multiplied together). is the number of time snapshots in the movie. This matrix can be decomposed into three matrices, which – without getting too much in the detail – are related to solving the eigenvalue problem of . Since is , we can’t technically solve an eigenvalue problem, but instead we can find the singular values (and corresponding vectors) of this matrix – hence POD is also called Singular Value Decomposition. These are as important as eigenvectors, in the sense that they form a set of basis vectors, othonormal in nature, that optimally span the space . In lay words: The singular vectors of are a set of nice pictures that represent the most variance in , and the singular values are the square root of this variance – meaning if has most of its content changing in a certain way, POD will capture that in its first few singular vectors/values.
POD is usually represented as this decomposition:
Where is the “mode matrix”, and each of its columns contains the flattened version of the mode – which can be unpacked by reversing the process of flattening used to generate the columns of . is a diagonal matrix with the singular values, and the modern SVD algorithms (like svd() in Matlab) return in descending order (i.e., the first diagonal entry is the most important singular value). What we’re actually after here – for the current discussion, at least – is . This is the “right singular vector matrix”, and each of its rows contains a series of coefficients that, when multiplied by the corresponding mode column, gives the “movie” of only that mode playing. It, in a sense, is a “time series matrix” when the unflattened dimension is time, and its coefficients can be analyzed to interpret what each mode is doing to the system under analysis. For example, you can try to take the Fourier Transform of a row of to understand if there’s any periodic behavior related to the corresponding mode in . It’s quite useful!
Some caveats and my two cents
Performing SVD in low-rank systems (i.e., when most of the energy in the eigenvalues of is contained within the first few entries) can be quite insightful, but sometimes we need long time series to get converged statistics (say, for example in the case of Fourier Analysis of , we need as many entries in as possible). This is particularly the case in experiments, where noise can contaminate the spectrum and spectral averaging can “clean up” our data by a good amount. In general, Fourier analysis needs long data sets to capture periodicity with a good amount of certainty. Therefore, we would like to perform SVD in the whole matrix so we can get the whole matrix, right? Well, yes, but it is not uncommon to run out of memory! For example, doing SVD on one of our data sets where was flooded the 128GB memory of our data processing computer! SVD is, unfortunately, an algorithm that needs quite a bit of memory – more specifically, we need memory, where is the shorter dimension. But if we assume (really, not a bad assumption in many cases) that the system is low-rank (say, only the first ~300 modes really matter), we could potentially perform SVD in the matrix, which is quite doable even in a laptop because the memory complexity scales with . The problem, is obviously, that now our matrix has only entries, which is not enough to do good Fourier analysis on. So what can we do to solve this?
Well, let’s remember that each column of is a basis vector to describe the data set. Let’s say we compute a cheaper mode matrix like the big matrix – let’s call it (where is the number of reduced dimensions used, in our example , whereas ). We can project every snapshot (column) of back into to get its entry in . To see the math better, let’s show how it works in matrix algebra:
Each column entry of is a flattened snapshot. Let’s look at how we generate one snapshot from the SVD:
So we multiply the full mode matrix and singular value matrix by a column vector that corresponds to the contribution of each mode, . Note the dimensions all cancel out, so we can “stick” our reduced matrix and its corresponding singular vectors in the mix, right? Let’s do that:
Where are the time coefficients of the particular snapshot we’re looking at (and in a sense, is what we’re after). Let’s do some math now – premultiply both sides by :
We get an identity matrix because is orthonormal. So let’s pre-multiply everything by the inverse of once more to get rid of it:
Or, more neatly:
This is actually quite neat. A column vector of the reduced rank right singular vector matrix is obtainable from ANY corresponding snapshot by projecting it onto the subspace of . This means we can obtain cheaply by simply randomly choosing a fraction of our data set to compose , and then perform this projection to the remainder of the data set in order to get all the columns of , for the first modes at least. This would be a snapshot-by-snapshot process, without the memory overhead of SVD. Of course, you can use some more “mature” algorithms, like randomized SVD, but for me the issue is that you need to load the data matrix twice: Once to produce the randomized range finder, and another time to compute the randomized SVD. When you can’t even fit the data set in memory and the data transfer time is really long, you don’t want to duplicate the loading process of the data matrix . This approach, although approximate, removes that need.
Of course, you don’t get the full benefit of SVD. In the end, is an approximation of , thus the projection will leave some stuff out. also is using less snapshots to be constructed, so you’ll have an error related to the modes themselves with respect to . But when lack of memory literally prevents you from doing SVD altogether and you’re most interested in analyzing (i.e., only the first modes of ), then you can still do the analysis to a pretty decent extent. Also, it might be a compelling way of storing time-resolved, 3D computational results without all the hard drive storage necessary (like a compression). So let’s look at some really nasty, noise contaminated, experimental data sets:
Results
Ok, so we’re looking at the wake of a NACA0020 airfoil that I used in a study I’m working on. The airfoil is at 0º angle of attack, but it still sheds coherent structures because of the shear layer instability. We want to pick up what are the frequencies of these coherent structures with Time-Resolved PIV, but this technique – even though it’s amazing – is a little tough to get to low noise levels. The individual vectors in the snapshots have uncertainties of the order of 10% of the mean flow! But as we will see, this is cake for POD – as long as there’s low-rank behavior happening.
So we construct the matrix by randomly sampling vector fields from the full data set. I used randperm() in Matlab for this part. Since the computer I’m using can handle up to about 3500 snapshots, we will look at 3500 snapshots (the full SVD) versus 350 snapshots (the reduced SVD), and then project the full matrix onto the subspace of to get the time coefficients of the first 350 modes.
Comparison of the time series of the first POD mode of the wing at ; “Full POD” corresponding to 3500 snapshots; “Random POD” corresponding to 350 snapshots and the projection method described here
As shown in the figure here, there’s not really much difference between the time series of the reduced, “random” POD, versus the full-fledged POD with 3500 snapshots. The difference in SVD computation, however, is quite a big deal:
Data Matrix size
Memory Consumption (Matlab SVD ‘econ’)
Computational Time
Full POD
5.7 GB
252 s
Reduced POD
too small to measure (<100MB)
7.1 s
SVD memory complexity for the case studied
As we can see, the difference is quite large in this “toy, but practical case”. Perhaps we could use more snapshots in the reduced POD case, but I also wanted to push it a little. The mode shapes look indistinguishable from each other, but of course we could get an euclidean distance metric (I didn’t really bother). Looking at the spectrum, we can see that the dynamics are pretty much indistinguishable in the first modes:
I’m not fully into the CFD business, but I think this simple technique could be used to compress CFD time series data, since we already know most flows do display low-rank behavior (and we are already doing these decompositions anyways to find this low-rank behavior!). In other words, I think one could: (1) run a DNS/LES solution until their statistics are converged (as is usual in the business), (2) run for some period of time while saving enough random snapshots to generate the snapshot matrix – you still need to run for a long-enough time, though – and then (3) perform POD on the snapshot matrix, and finally (4) run for as long as necessary, and project every snapshot onto this random POD basis to get the matrix (low memory consumption). This enables one to save the matrix, along with the first few modes of onto a file, and in the future reconstruct the entire simulation time series (to reasonable accuracy) for further analysis. Obviously the analysis will be limited to the compression accuracy and the time span of the capture process, so one has to be aware of that!
Well, perhaps I’ll try that in the future. But for now, I’ll leave the idea floating so someone can perhaps find some use to it.
I'm a brazilian Mechanical Engineer and PhD, with research interests in aeroacoustics, flow control, flow diagnostics and heat transfer. In the past I've worked as a refrigeration systems designer and later as an R&D specialist at a refrigeration contracting company, researching for new products to push the industrial refrigeration market technologies forward. I then did my PhD at Florida State University in experimental aerodynamics, spending a couple years after as a postdoc working in supersonic jet noise production and other projects. In 2022, I moved to Los Alamos National Lab, where I developed 3D tomographic flow diagnostics for the Extreme Fluids group led by Dr. John Charonko.
View all posts by Fernando Zigunov